 Por Héctor José Iaconis.
Por Héctor José Iaconis.
El auge de las nuevas tecnologías nos ha permitidos digitalizar, primero por medio de escáneres planos, luego con cámaras fotográficas y, más tarde, también con teléfonos celulares, documentos históricos vinculados con la historia de 9 de Julio. A lo largo de los años, hemos podido reunir diversos documentos manuscritos digitalizados que han sido una fuente muy importante para el estudio de aspectos vinculados con el pasado de la comunidad.
A diferencia de los documentos impresos, cuyo procesamiento ya podía hacerse desde hace muchos años, se presentaba un problema a la hora de procesar documentos históricos manuscritos digitalizados en grandes volúmenes. Durante largo tiempo, el procesamiento de la información contenida en ellos era absolutamente manual y directa sobre la fuente de estudio. Sin embargo, desde hace poco tiempo, con la introducción de modelos de Handwritten Text Recognition (HTR) o Reconocimiento Óptico de Texto Manuscrito, basados en redes neuronales profundas, el acceso a estos corpus documentales resulta mucho más fácil.
En el campo de la inteligencia artificial (IA), día a día, los cambios se verifican de manera vertiginosa, enriqueciéndose considerablemente aquellos que, quizá, hace un mes o un año atrás, tenían mayores limitaciones. Entre las herramientas más conocidas, usadas para la transcripción de manuscritos históricos se encuentran:
- Transkribus: Como se ha discutido, es una de las plataformas más conocidas y completas. Desarrollada por la cooperativa READ-COOP, utiliza modelos de deep learning para HTR. Posee, en efecto, modelos de IA entrenables y capacidades de layout analysis.
- eScriptorium: Se trata de una plataforma de código abierto y basada en la web, desarrollada en colaboración con el Laboratoire de Recherche Historique Rhône-Alpes (LARHRA) y otras instituciones. A diferencia de Transkribus, eScriptorium es de uso libre y se basa en la misma tecnología de reconocimiento HTR (Kraken/Pyltr). Es una opción atractiva para instituciones con recursos técnicos que deseen alojar su propia instancia o para proyectos que busquen una solución de código abierto.
- Tesseract OCR: Aunque es principalmente un motor de Reconocimiento Óptico de Caracteres (OCR) para texto impreso, la versión más reciente de Tesseract, en combinación con técnicas de preprocesamiento de imágenes, puede ser utilizada para el reconocimiento de algunos tipos de escritura manuscrita. Es una herramienta de código abierto desarrollada por Google, y su principal ventaja es su disponibilidad y adaptabilidad, aunque su rendimiento con escritura manuscrita compleja es significativamente menor que el de las plataformas especializadas en HTR.
A las herramientas indicadas presentemente, pueden añadirse Kraken y Arkímedes (la plataforma de la Universidad de Granada, España, que utiliza modelos de IA para la transcripción y el análisis de documentos históricos). Otra plataforma interesante es FromThePage la cual, aunque no se basa puramente en IA para la transcripción inicial, ofrece la transcripción colaborativa en línea, coordinando el trabajo de voluntarios y expertos, y su integración con tecnologías de transcripción automática (incluyendo Transkribus) para agilizar el proceso y validar los resultados. Según los expertos, FromThePage, ideal para proyectos de crowdsourcing de gran escala.
Además, otras herramientas de IA son muy apropiadas para el trabajo con manuscritos históricos, con uso más generalizado: ChatGPT y Gemini, completamente accesibles para toda la comunidad.
I. TRANSKRIBUS
Hoy nos ocupares de Transkribus, ofreciendo como ejemplo la transcripción de un documento histórico manuscrito datado en 9 de Julio en 1892. Tal como lo referimos precedentemente, esta plataforma digital desarrollada para el reconocimiento automático de texto manuscrito (HTR), mediante IA fue diseñada originalmente en el marco del proyecto READ (Recognition and Enrichment of Archival Documents), financiado por la Unión Europea. En los últimos años se ha convertido en una herramienta clave para archivístas, paleógrafos e historiadores, como así también para estudiosos y usuarios de otros campos. En pocas palabras, se puede definir como una plataforma de IA que permite transcribir, editar, etiquetar y exportar documentos históricos de modo automatizado, facilitando enormemente el acceso al patrimonio manuscrito digitalizado de la comunidad.
En noviembre de 2024, Transkribus desarrolló “Spanish Sage”, un modelo versátil para el reconocimiento de textos manuscritos e impresos en español, entrenado con Coloso Español. Este permite gestionar documentos manuscritos muy variados, desde medievales hasta modernos. Diseñado para uso general, ofrece un rendimiento robusto en diversas escrituras y períodos del idioma español y es, consiguientemente, el que hemos usado para la transcripción de manuscritos referidos a la historia de 9 de Julio.
Desde luego, para ello se requiere contar con una tarea previa de digitalización de los documentos históricos, en lo posible de forma organizada, sistematizada y sostenida. Una realidad que, desafortunadamente, no se está verificado hoy por hoy en los archivos y repositorios oficiales existentes en la ciudad de 9 de Julio
Cabe recordar que, Transkribus, fue desarrollado a partir del año 2015 por el equipo de investigación de la Universidad de Innsbruck (Austria), dentro del proyecto READ. Desde su lanzamiento, ha evolucionado de una plataforma experimental a una solución consolidada, con más de cien mil usuarios registrados y miles de modelos HTR entrenados. Actualmente es gestionado por la cooperativa READ-COOP SCE, que promueve el uso colaborativo y sostenible de tecnologías para el procesamiento de documentos históricos.
II. SU FUNCIONAMIENTO
En una descripción simple, podemos decir que Transkribus funciona mediante una combinación de algoritmos de visión por computadora, aprendizaje profundo (deep learning) y segmentación textual. El usuario sube una imagen escaneada de un manuscrito, segmenta el documento (zonas, líneas, palabras) y aplica un modelo HTR preentrenado o personalizado. El sistema reconoce el texto línea por línea, generando una transcripción editable que puede ser exportada en diversos formatos (TXT, TEI-XML, PDF, ALTO XML).
Entre las ventadas del uso de Transkribus se encuentran:
– Ahorro de tiempo en la transcripción manual.
– Reducción de errores humanos.
– Posibilidad de entrenar modelos personalizados.
– Interfaz gráfica para edición colaborativa.
– Exportación en formatos interoperables.
Según los expertos, con el uso de este modelo puede verificarse algunas desventajas:
– Dependencia de calidad de escaneo y segmentación (aunque no siempre es así, pues hemos utilizado en varias ocasiones manuscrito digitalizados con calidad deficiente, como en el caso del archivo personal de Ángel Rodríguez que fue digitalizado mediante un teléfono móvil).
– Requiere validación humana en textos complejos.
– Modelos preentrenados no siempre se adaptan a todas las escrituras.
– El entrenamiento de nuevos modelos requiere recursos técnicos.
– Algunas funciones avanzadas requieren suscripción paga.
III. EJEMPLO DE USO DE TRANSKRIBUS CON UN DOCUMENTO HISTORICO LOCAL
Desde hace tiempo, Transkribus viene aplicándose con éxito en diversos contextos: archivos latinoamericanos, registros parroquiales, protocolos notariales y documentos municipales. En todos ellos, la herramienta ha mostrado una notable eficacia al reducir los tiempos de transcripción y facilitar la investigación en humanidades digitales, historia social y ciencias archivísticas.
Este apartado presentaremos el caso concreto de uso de Transkribus aplicado a un documento manuscrito administrativo del siglo XIX, conservado en expediente del Archivo de Gestión de la Municipalidad de 9 de Julio. Se trata de una solicitud presentada por Cipriana C. de Melgar en 1892 para la adquisición de fosas en el cementerio municipal de 9 de Julio.
El expediente al que corresponde este documento fue digitalizado por el autor a finales de 2001, con baja resolución, por medio de PC – Scanner HP Scanjet 2200 C., siendo su tipo de archivo de fuente de saluda Joint Photographic Experts Group (JPG). Luego fue compaginado con Portable Document Format (PDF) de Adobe Systems y almacenado por medio de CD-Room. En consecuencia, para la transcripción con IA de este documento, usaremos esta fuente de resolución baja, pues de otro modo sería menester volver a digitalizarlo con mayor resolución.
Características del documento: Solicitud de compra de fosa perpetúa en el Cementerio de 9 de Julio. Fecha: 14 de octubre de 1892. Lugar: Nueve de Julio, Provincia de Buenos Aires.
Ubicación física del documento original: Archivo de Gestión de la Municipalidad de 9 de Julio ubicado en el Palacio Municipal, segundo piso (ático/desván/altillo). Signatura topográfica: Documentos del Departamento Ejecutivo de la Municipalidad de 9 de Julio, Cuerpo sin numerar [estantería de madera, ubicada en pared norte], anaquel 4.
Soporte del expediente original: Papel. Hojas con timbre oficial, Ley de Sellos. Hojas con filigrana y marcas de agua. Un croquis en tela, trazado con tinta estilográfica ferrogálica.
Formato del documento digital: manuscrito cursivo, tinta negra sobre papel oficio con sellos fiscales.
Fecha de digitalización: 12 de diciembre de 2001.

Contenido: Cipriana C. de Melgar solicita al Intendente Municipal autorización para comprar tres fosas a perpetuidad en el cementerio local. El documento está firmado por testigos y registra formalmente una gestión administrativa frecuente en el contexto histporico del siglo XIX.
Resultado del reconocimiento con Transkribus (modelo Spanish Sage):
Reconocimiento automático (HTR) – Resultado parcial:
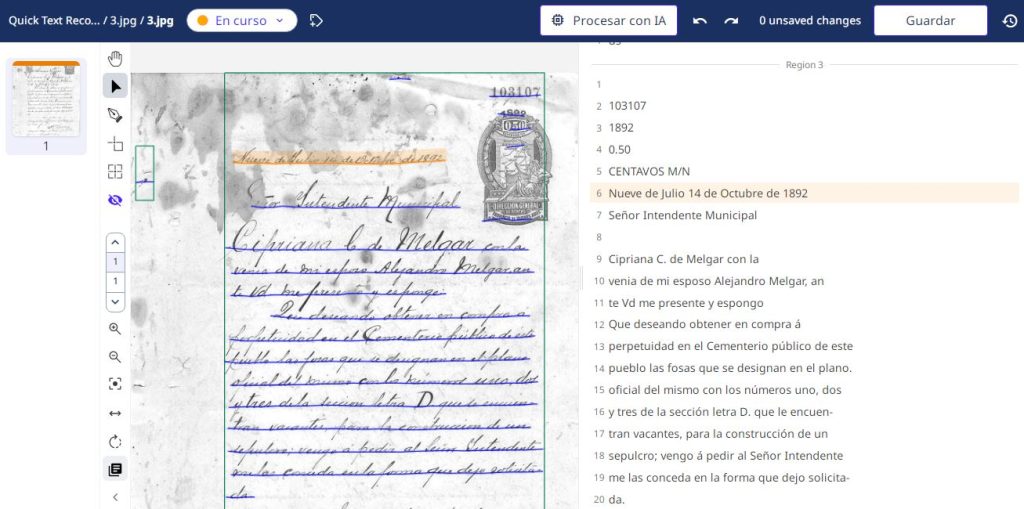
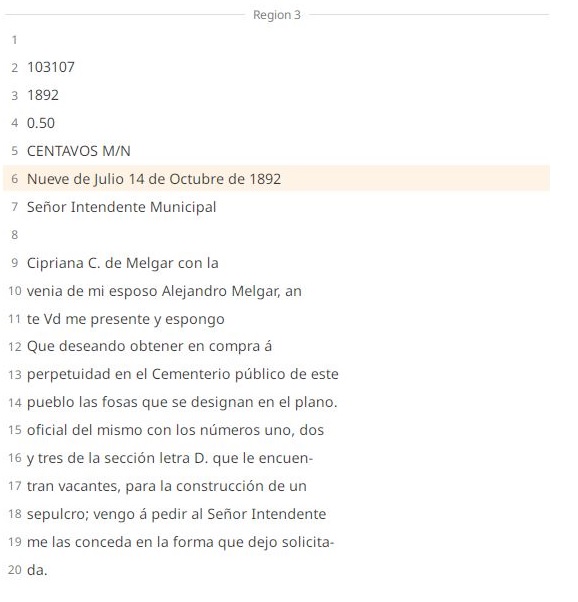
El modelo Spanish Sage reconoció correctamente: la fecha con formato verbal completo, nombres propios, estructuras de solicitud administrativa y ortografía antigua.
Este ejemplo ilustra una ruta técnica efectiva de trabajo archivístico con Transkribus:
1. Digitalización y carga:
– Escaneo del documento a 300 dpi.
– Subida a Transkribus Web con metadatos básicos.
– Clasificación: «Solicitudes Municipales / Nueve de Julio / Cementerio / 1892».
2. Segmentación del texto:
– Segmentación automática con corrección manual de líneas.
– Etiquetado de zonas: body, signature, marginalia, stamp.
3. Reconocimiento HTR:
– Aplicación del modelo Spanish Sage.
– Alta calidad a pesar de manchas, tinta tenue y sello fiscal.
4. Corrección y anotación semántica:
– Corrección manual mínima.
– Posibilidad de etiquetar XML-TEI con <persName>, <placeName>, <date>.
<persName>Cipriana C. de Melgar</persName>
<date when=»1892-10-14″>14 de Octubre de 1892</date>
<placeName>Nueve de Julio</placeName>
5. Exportación e integración:
– Posibilidad de exportación como PDF, TXT y TEI-XML.
– Posible integración con Omeka S o AtoM para archivo digital.
6. Herramientas auxiliares usadas para el reconocimiento del documento que nos ocupa:
| Tarea: | Herramienta: |
| Reconocimiento HTR | Spanish Sage (Transkribus) |
| Corrección manual | Transkribus Web Editor |
| Visualización PDF | Adobe Acrobat, Okular |
| Análisis contextual | Excel, Voyant Tools |
Con este ejemplo podemos observar cómo un documento administrativo municipal del siglo XIX, de escritura manuscrita y deteriorado físicamente, puede ser transcrito automáticamente con alta fidelidad. El reconocimiento realizado con Spanish Sage evita la necesidad de entrenar un modelo propio, aunque es posibilidad siempre está abierta en las plataformas de IA.
En próximas notas, mediante la utilización de otros documentos históricos manuscritos, observaremos las posibilidades que ofrecen otros modelos, tales como ChatGPT, Gemini o eScriptorium, con los cuales se pueden alcanzar también resultados muy interesantes.
IV. PASO A PASO
Para quienes se están iniciando en el uso de estas herramientas, ofrecemos a continuación un breve instructivo sobre cómo efectuar una transcripción de documentos manuscritos en Transkribus con el Modelo Spanish Sage. Tomamos como ejemplo el mismo documento histórico:
Paso 1. Preparar el documento digitalizado:
- Formato del archivo: JPG, PNG o PDF.
• Resolución recomendada: 300 dpi o superior para asegurar la legibilidad.
• Nombre sugerido del archivo: Utilizar un nombre descriptivo (ej. Solicitud_Cementerio_1892.jpg).
Ejemplo usado: una solicitud manuscrita de Cipriana C. de Melgar al Intendente Municipal de Nueve de Julio, fechada el 14 de octubre de 1892.
Paso 2. Subir el archivo a Transkribus:
- Debemos iniciar sesión en https://app.transkribus.org
2. Crear una colección nueva (por ejemplo, “Documentos Municipales 1890s”).
3. Cargar el archivo desde tu dispositivo.
4. Una vez subido, debemos seleccionar el documento en la colección y haz clic en “Abrir en el Editor”.
Paso 3. Segmentar el documento:
- Transkribus detectará automáticamente las zonas de texto y líneas.
• Podemos revisar y corregir la segmentación con la herramienta de edición:
– Rectificar las regiones si hay encabezados, márgenes, firmas.
– Ajustar las líneas en caso de que estén partidas o agrupadas incorrectamente.En el ejemplo, el encabezado (“Nueve de Julio 14 de Octubre de 1892”), el cuerpo de la solicitud y las firmas al pie fueron segmentadas.
Paso 4. Aplicar el modelo Spanish Sage:
- Debemos realizar clic en el botón “Reconocer texto (HTR)”.
2. Seleccionar el modelo llamado Spanish_SAGE.
3. Aquí debemos aceguarnos de marcar “todas las páginas” o “todas las líneas”.
4. Iniciar el proceso. Puede tardar unos segundos.
Paso 5. Revisar y corregir la transcripción
- Debemos acceder al panel derecho donde aparece el texto generado.
• Leer detenidamente y corregir manualmente los errores.
• Debemos prestar especial atención a:
– Tildes y signos de puntuación.
– Letras confusas (como «n» por «u», o «r» por «v»).
– Nombres propios y cifras.
Paso 6. Exportar el resultado
- Si realizamos clic en “Exportar”, el modelo nos permite escoger el formato deseado:
– TXT para texto plano.
– DOCX para edición en Word.
– XML ALTO/TEI para integraciones archivísticas avanzadas.
Consejos adicionales: En el caso de trabajar con varios documentos similares, debe considerarse la posibilidad de entrenar un modelo personalizado. También es recomendable la opción de colaboración si otros investigadores participan en la transcripción.
Hasta la próxima…
V. BIBLIOGRAFIA
Recomendamos especialmente, para una introducción en la temática, la tesis de Nikolina Milioni sobre Transcripción automática de documentos históricos. Transkribus como herramienta para bibliotecas, archivos y académicos (Automatic Transcription of Historical Documents. Transkribus as a Tool for Libraries, Archives and Scholars), disponible en https://www.diva-portal.org/smash/get/diva2:1437985/FULLTEXT01.pdf
Este brillante trabajo, junto a otros artículos publicados más recientemente, ofrecen un panorama muy integrador sobre las funcionalidades de Transkribus y las posibilidades de aplicación en el estudio de documentos históricos manuscritos procedentes de archivos de la ciudad de 9 de Julio:
- Aranda García, Nuria. «Humanidades Digitales y literatura medieval española: la integración de Transkribus en la base de datos COMEDIC.» En Historias Fingidas, número especial 1 (2022): 127-149. Disponible en https://dialnet.unirioja.es/descarga/articulo/8768380.pdf
- Ayuso García, Manuel. «Las ediciones de Arnao Guillén de Brocar de BECLAR transcritas con ayuda de Transkribus y OCR4all: creación de un modelo para la red neuronal y posible explotación de los resultados.» En Historias Fingidas, número especial 1 (2022): 151-173. Disponible en https://dialnet.unirioja.es/descarga/articulo/8768378.pdf
- Bermúdez Carreño, Jaime. «Inteligencia artificial para la transcripción de letra itálica española del siglo XVIII: Transkribus como herramienta para las humanidades digitales.» En Revista de Humanidades Digitales 8 (2023): 109-127. Disponible en https://revistas.uned.es/index.php/RHD/article/view/38111/28264
- Capurro, Carlotta, Vera Provatorova y Evangelos Kanoulas. «Experimenting with Training a Neural Network in Transkribus to Recognise Text in a Multilingual and Multi-Authored Manuscript Collection.» En Heritage 6, n.º 12 (2023): 7482–7494. Disponible en https://www.mdpi.com/2571-9408/6/12/392
- Cossío Olavide, Mario. «Editando el Lucidario de Sancho IV: la transmisión manuscrita y la edición digital». En Sendas del hispanismo: bmárgenes, centros y convergencia : actas del XXI Congreso de la Asociación Internacional de Hispanistas (Neuchâtel 2023), editado por Juan Pedro Sánchez et al., Iberoamericana Editorial Vervuert, 2025. Disponible en https://ojs.studiespublicacoes.com.br/ojs/index.php/cadped/article/view/14144/7987
- Muehlberger, Guenter, Louise Seaward, Melissa Terras, Sofia Ares Oliveira, Vicente Bosch, Maximilian Bryan, Sebastian Colutto, et al. «Transforming scholarship in the archives through handwritten text recognition: Transkribus as a case study.» En Journal of Documentation 75, n.º 5 (2019): 954-976. Disponible en https://www.emerald.com/jd/article-pdf/75/5/954/1398560/jd-07-2018-0114.pdf
- Nockels, Joseph, Paul Gooding y Melissa Terras. «Are Digital Humanities platforms facilitating sufficient diversity in research? A study of the Transkribus Scholarship Programme.» En Digital Scholarship in the Humanities 40, Supl. 1 (2025): i46-i65. Disponible en https://academic.oup.com/dsh/article-pdf/40/Supplement_1/i46/59648098/fqae018.pdf
- Polomac, Vladimir, y Tamara Lutovac Kaznovac. «Automatic Recognition of Serbian Medieval Manuscripts by Applying the Transkribus Software Platform: Current Situation and Future Perspectives.» En Zbornik Matice srpske za filologiju i lingvistiku 64, n.º 2 (2021): 256-264. Disponible en https://scidar.kg.ac.rs/bitstream/123456789/17916/1/Automatic%20Recognition%20of%20Serbian%20Medieval%20Manuscripts.pdf
- Torterolo-Orta, Yanco Amor, Jaione Macicior-Mitxelena, Marina Miguez-Lamanuzzi, y Ana García-Serrano. «Transcribing Spanish Texts from the Past: Experiments with Transkribus, Tesseract and Granite.» Preprint, arXiv: 2507.04878 (julio de 2025). Disponible en https://arxiv.org/pdf/2507.04878