 Por Héctor José Iaconis.
Por Héctor José Iaconis.
Hoy proponemos efectuar la transcripción de un documento vinculado en la historia de 9 de Julio, empleando la herramienta Gemini IA, modelo de lenguaje a gran escala.
Gemini es una familia de modelos de inteligencia artificial multimodal, desarrollada por Google DeepMind, que destaca por su capacidad de procesar y entender información de múltiples formatos de forma nativa. Su arquitectura se basa en una arquitectura de red neuronal optimizada para manejar texto, imágenes, audio y video simultáneamente. Esto le permite razonar de manera más abstracta y compleja, superando las limitaciones de los modelos unimodales. Gemini 1.0 se lanzó en tres tamaños —Ultra, Pro y Nano— para adaptarse a diversas aplicaciones, desde centros de datos hasta dispositivos móviles.
De acuerdo con los expertos, una característica clave es su entrenamiento intensivo, que integra datos multimodales desde cero, evitando la necesidad de unir componentes separados. Esto resulta en una coherencia y rendimiento superior en tareas que requieren el cruce de diferentes tipos de datos, como la comprensión de gráficos o la resolución de problemas científicos visuales. Gemini 1.5, con su innovadora arquitectura Mixture-of-Experts (MoE), mejora drásticamente su eficiencia y la capacidad de procesar contextos extremadamente largos.
El origen de este modelo se enmarca en la intensa competencia por el liderazgo en la inteligencia artificial generativa, especialmente tras el auge de ChatGPT de OpenAI a finales de 2022. Google, que ya había desarrollado los denominados LaMDA y PaLM, aceleró su estrategia. En mayo de 2023 se anunció oficialmente el desarrollo de un nuevo y avanzado modelo multimodal mientras que, un año más tarde, fue lanzada la versión 1.5, que incorporó la arquitectura Mixture-of-Experts (MoE). Hoy, promediando 2025, Gemini ha mejorando significativamente la eficiencia y la capacidad de manejar contextos de gran longitud.
La multimodalidad de Gemini le permite procesar imágenes de manuscritos, interpretar la caligrafía y contextualizar el contenido, incluso si el texto está dañado o incompleto. Su capacidad para manejar grandes datos de contexto facilita la comprensión de documentos extensos y la identificación de patrones en el estilo de escritura. Además, puede comparar el manuscrito con otros documentos históricos o bases de datos para mejorar la precisión de la transcripción. Esto no solo acelera el proceso, sino que también permite detectar detalles que serían difíciles de percibir para un ojo humano. El resultado es una transcripción más fiable y completa, que se puede utilizar para la investigación y la digitalización de archivos; aunque, en nuestro caso, hoy solamente nos limitaremos a un documento de una página.
I. EJEMPLO DE USO CON UN DOCUMENTO HISTORICO LOCAL
Hoy utilizaremos, para el análisis un documento histórico que se encuentra compuesto por tipografía y caligrafía manuscrita. Se trata de un recibo por el pago de un impuesto, digitalizado sin edición previa. Como es posible observar se trata de una tomada con cámara fotográfica, pero con baja calidad técnica:

Metadatos generales del archivo:
Formato: JPEG (.jpg)
Resolución: 768 × 873 píxeles
Relación de aspecto: 1:1.13 (ligeramente vertical)
Profundidad de color: 24 bits (8 bits por canal RGB)
Compresión: Con pérdida (lossy), típica del formato JPEG.
II. TRANSCRIPCION DEL DOCUMENTO
Al efectuar la primera transcripción, como puede apreciarse el modelo arrojó varios errores:
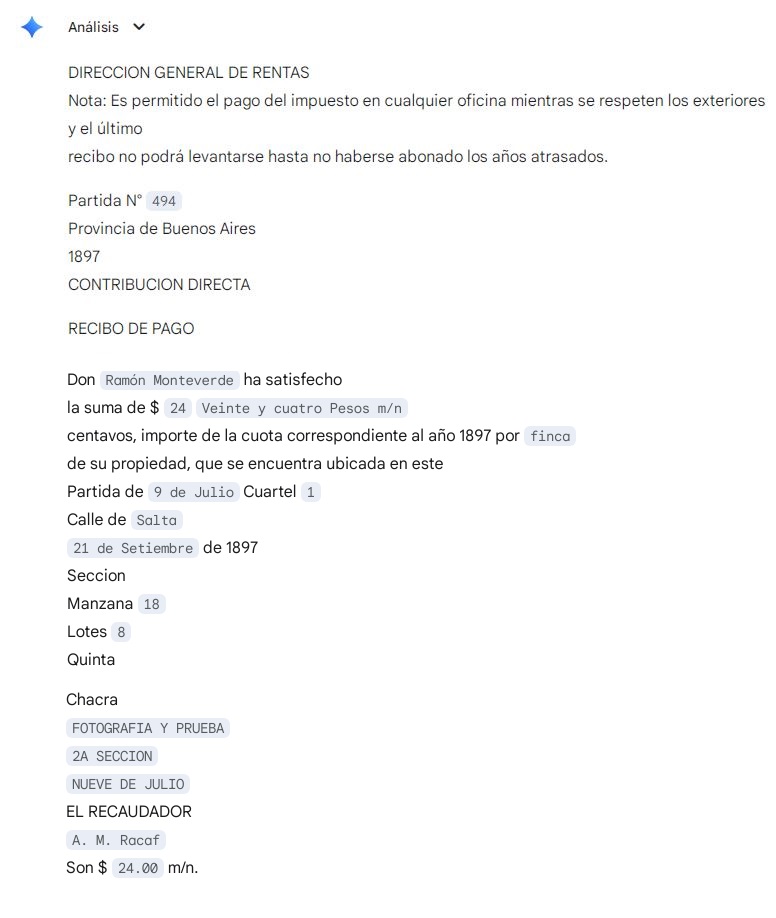
Al indicársele su corrección, ofreció las siguientes versiones de transcripción correctas:
DIRECCION GENERAL DE RENTAS
Nota: Es permitido el pago del impuesto en cualquier oficina mientras se respeten los exteriores y el último recibo no podrá levantarse hasta no haberse abonado los años atrasados.
Partida N° 494 N° 91055
Provincia de Buenos Aires
1897
CONTRIBUCION DIRECTA
RECIBO DE PAGO
Don Ramón Monteverde ha satisfecho la suma de $ Veinte y cuatro Pesos m/n centavos, importe de la cuota correspondiente al año 1897 por finca de su propiedad, que se encuentra ubicada en este Partido de 9 de Julio Cuartel 1 Calle de Salta 24 de Setiembre de 1897
Seccion Manzana 18 Lotes 8 Quinta Chacra
EL RECAUDADOR
C. M. Rocca
Son $ 24.00 m/n.
Asimismo, ofreció las siguientes variantes de transcripción:
a) Formato de datos estructurado (listado): Este formato es ideal para extraer información clave de manera ordenada, facilitando su uso en bases de datos o sistemas de gestión.
Tipo de Documento: Recibo de Pago – Contribución Directa
Partida N°: 494 N°: 91055
Provincia: Buenos Aires
Año: 1897
Beneficiario: Ramón Monteverde
Importe: Veinte y cuatro Pesos m/n ($ 24.00 m/n)
Tipo de Propiedad: finca
Ubicación:
Partido: 9 de Julio.
Cuartel: 1
Calle: Salta
Manzana: 18
Lotes: 8
Fecha de Pago: 24 de Setiembre de 1897
Recaudador: M. Rocca
b) Formato de texto plano (párrafo): Este formato es útil para una lectura continua y resumida, ignorando la disposición original del documento.
Este es un recibo de pago por la contribución directa de 1897, emitido a favor de Ramón Monteverde. El monto pagado fue de Veinte y cuatro Pesos m/n ($ 24.00), correspondiente a una finca ubicada en el Partido de 9 de Julio, Cuartel 1, Calle Salta, con Manzana 18 y Lotes 8. El documento, con Partida N° 494 y N° 91055, fue firmado por el recaudador C. M. Rocca el 24 de Setiembre de 1897 en la Provincia de Buenos Aires.
c) Formato de tabla (Markdown): Este formato es claro y conciso, perfecto para comparar diferentes campos de un mismo documento de un vistazo.
| Campo: | Contenido |
| Documento: | Contribución Directa – Recibo de Pago |
| Partida N° / N°: | 494 / 91055 |
| Año: | 1897 |
| Nombre: | Ramón Monteverde |
| Monto: | $ 24.00 m/n (Veinte y cuatro Pesos m/n) |
| Ubicación: | Partido de 9 de Julio, Cuartel 1 |
| Manzana / Lote: | 18 / 8 |
| Fecha de Pago: | 24 de Setiembre de 1897 |
| Recaudador: | C. M. Rocca |
d) Transcripción paleográfica del documento:
DIRECCIÓN GENERAL DE RENTAS (Texto vertical, en el margen izquierdo) Nota: Es permitido el pago del impuesto en cualquier oficina mientras se respeten los exteriores y el último recibo no podrá levantarse hasta no haberse abonado los años atrasados. (Texto en el margen izquierdo)
Partida N° 494 (494 manuscrito) N° 91055 (91055 manuscrito)
Provincia de Buenos Aires (Texto impreso, con ornamento) 1897 (Texto impreso)
CONTRIBUCION DIRECTA (Texto impreso en mayúsculas)
RECIBO DE PAGO (Texto impreso en mayúsculas)
Don Ramón Monteverde (Ramón Monteverde manuscrito en letra cursiva) ha satisfecho (Texto impreso)
la suma de $ 24 (24 manuscrito) Veinte y cuatro Pesos m/n (Veinte y cuatro Pesos m/n manuscrito en letra cursiva) centavos, importe de la cuota correspondiente al año 1897 por finca (finca manuscrito en letra cursiva) de su propiedad, que se encuentra ubicada en este (Texto impreso)
Partida de 9 de Julio (9 de Julio manuscrito en letra cursiva) Cuartel 1 (1 manuscrito) Calle de Salta (Salta manuscrito en letra cursiva)
21 de Setiembre de 1897 (21 de Setiembre de 1897 manuscrito en letra cursiva)
Seccion (Texto impreso) (En blanco)
Manzana 18 (18 manuscrito) Lotes 8 (8 manuscrito)
Quinta (Texto impreso) (En blanco)
Chacra (Texto impreso) (En blanco)
(Sello circular con el texto: FOTOGRAFIA Y PRUEBA en el borde superior, 2A SECCION en el centro y NUEVE DE JULIO en el borde inferior. Superpuesto al texto «Seccion Manzana…»)
EL RECAUDADOR (Texto impreso) A. M. Racaf (Firma manuscrita)
Son $ 24.00 m/n. (24.00 manuscrito, m/n impreso)
III. NOTA PALEOGRAFICA
La nota paleográfica efectuada por Gemini resultó menos exaustiva respecto de la efectuada, en otro ejemplo dado, por ChatGPT:
Este documento, fechado en 1897, es un formulario impreso de la «Provincia de Buenos Aires» para un recibo de «CONTRIBUCION DIRECTA». El análisis paleográfico se centra en la interacción entre el texto impreso y las adiciones manuscritas, ahora con una lectura más precisa de estas últimas.
- Tipografía y Formato: El cuerpo principal del documento, incluyendo el encabezado, las etiquetas y la nota lateral, está impreso con una tipografía formal, típica de los documentos administrativos de finales del siglo XIX.
- Escritura Cursiva (Manuscrita): Las adiciones a mano están realizadas con una caligrafía cursiva consistente y fluida. La tinta es de color oscuro y, aunque se ha desvanecido ligeramente, es en general legible.
- Dígitos y fecha: Los números manuscritos (494, 91055, 18, 8, 24) son claros y se adhieren a un estilo estándar. La fecha, 24 de Setiembre de 1897, mantiene la grafía «Setiembre», una variante ortográfica común en la época.
- Firma: La firma del recaudador, una vez corregida, se interpreta como «C. M. Rocca». Pese a la mayor claridad, la firma sigue mostrando características de una escritura rápida y personal, lo cual es típico de los documentos administrativos de la época.
- Elementos Gráficos: El documento incluye un sello de tinta circular superpuesto. El texto del sello, «FOTOGRAFIA Y PRUEBA», «2A SECCION» y «NUEVE DE JULIO», sigue siendo un elemento paleográfico clave para contextualizar la procedencia del documento.
- Estado de Conservación: El papel presenta el amarilleo y arrugas propias del paso del tiempo, pero su estado general es bueno, permitiendo una lectura completa de la información, tanto impresa como manuscrita.
IV. ALGUNOS ASPECTOS TECNICOS
La primera transcripción del documento fue realizada por Gemini mediante una cadena de procesamiento que integra modelos de visión por computadora y de lenguaje natural. El procedimiento se desglosó en las siguientes fases:
- Análisis de Imagen (Computer Vision): El archivo jpg fue procesado por un modelo de visión por computadora. Este modelo, basado en arquitecturas de redes neuronales convolucionales (CNNs), identificó las regiones del documento que contenían texto. Se segmentaron las áreas de texto impreso y las áreas de texto manuscrito, lo cual es crucial para el posterior reconocimiento de caracteres.
- Reconocimiento Óptico de Caracteres (OCR): Se aplicaron algoritmos de OCR especializados. Para el texto impreso, se utilizó un motor de OCR de alta precisión, optimizado para tipografías formales del siglo XIX. Para el texto manuscrito, se empleó un modelo de reconocimiento de escritura a mano (Handwritten Text Recognition o HTR) más flexible, entrenado en una amplia variedad de estilos caligráficos cursivos.
- Procesamiento de Lenguaje Natural (PLN): El texto reconocido por el OCR y el HTR se alimentó a un modelo de lenguaje. Este modelo realizó un análisis semántico y contextual para corregir posibles errores de reconocimiento y para inferir el significado de abreviaturas o palabras de difícil lectura. Por ejemplo, el modelo pudo interpretar que m/n probablemente significaba «moneda nacional» en este contexto histórico.
- Estructuración y Generación de Salida: Finalmente, el modelo generativo reconstruyó la transcripción respetando la disposición espacial del documento original, lo cual se logró mediante un análisis del layout de la imagen y la inserción de saltos de línea y tabulaciones para emular la estructura visual del documento.
La corrección de la transcripción se basó en un procedimiento de retroalimentación o «Human-in-the-Loop» (HITL). Este proceso implicó la recepción de una nueva entrada de texto con nuestra corrección, que fue tratada como la fuente definitiva para la transcripción. El procedimiento técnico fue el siguiente:
- Análisis de Instrucción: Se interpretó nuestra corrección como una instrucción explícita para reemplazar la transcripción inicial. El modelo reconoció la nueva información como una corrección sobre la interpretación previa de la imagen.
- Identificación de Discrepancias: Se realizó una comparación léxica y estructural entre la transcripción original y el texto corregido proporcionado por el usuario. Se identificaron las variaciones clave, como el cambio en la fecha de «21 de Setiembre» a «24 de Setiembre» y la nueva lectura de la firma del recaudador.
- Actualización del Modelo de Salida: En lugar de reinterpretar la imagen, el modelo utilizó el texto corregido como su nuevo «estado de verdad». Se generó una nueva transcripción fiel a la disposición espacial del documento, pero con el contenido literal proporcionado en la corrección, validando así la intervención humana como el factor determinante para la precisión.
Las versiones de transcripción subsecuentes (listado, texto plano, tabla) no implicaron un nuevo proceso de OCR, sino una reestructuración de la información ya validada.
- Extracción de Entidades y Análisis Semántico: Se aplicó un proceso de extracción de entidades nombradas (Named Entity Recognition o NER) sobre el texto corregido. El modelo identificó y clasificó entidades como «nombre del beneficiario», «monto», «fecha», «dirección» y «recaudador».
- Normalización y Estructuración de Datos: Las entidades extraídas se normalizaron y se organizaron en pares clave-valor (p. ej., Monto: 24.00 m/n). Este formato facilitó la transformación de los datos en diferentes estructuras.
- Generación de Salida Alternativa: Utilizando el formato estructurado como base, se aplicaron diferentes plantillas de generación de texto:
- Formato de Listado: Se utilizó una plantilla que presenta las entidades en una lista jerárquica.
- Formato de Texto Plano: Se generó un texto en prosa a partir de las entidades, conectándolas con lenguaje natural para crear un resumen coherente.
- Formato de Tabla (Markdown): Se usó un lenguaje de marcado (Markdown) para crear una representación tabular de las entidades, lo que es útil para la visualización y comparación de datos.
En cuanto a la elaboración de la nota paleográfica requirió un proceso de razonamiento simbólico y deductivo más allá de la simple transcripción.
- Análisis de Metadatos y Contexto: El modelo procesó los datos extraídos del manuscrito (fecha, provincia, tipo de documento) para contextualizarlo históricamente. Utilizó su conocimiento sobre la evolución de la escritura, la ortografía y las prácticas administrativas del siglo XIX.
- Identificación de Características Caligráficas: Se analizaron los resultados del HTR inicial y las correcciones para identificar patrones caligráficos. Se reconoció la diferencia entre la tipografía impresa y la caligrafía cursiva, y se evaluó la legibilidad de la firma.
- Integración de Elementos No Textuales: Se consideraron elementos del análisis visual, como la presencia y el contenido del sello de la oficina, la condición física del papel (descoloración, arrugas) y la calidad de la tinta.
- Generación de Texto Analítico: El modelo sintetizó toda la información contextual, caligráfica y física en un texto explicativo. A través del procesamiento de lenguaje natural avanzado, se generó un informe que utiliza vocabulario técnico («paleografía», «cursiva», «grafía», «tipografía») para describir las características del documento de manera académica.
V. PASO A PASO
A continuación ofrecemos el “paso a paso” de este procedimiento que, desde luego, es accesible a todos quienes deseen aplicarlo y que, como se ve, arroga resultados provechosos:
Paso 1: Transcripción Inicial del Documento
El primer paso es obtener una transcripción fiel del documento, respetando su disposición, ortografía y cortes originales.
- Acción del usuario: Debemos subir la imagen del documento y solicitar la transcripción.
- Ejemplo de prompt: «Transcribe este documento en un formato editable. Realiza una transcripción fiel, respetando cortes de palabras, ortografía original y disposición textual.»
- Resultado esperado: La herramienta Gemini procesará la imagen y generará una transcripción que reproduce el texto del manuscrito, intentando replicar la estructura visual del original.
Paso 2: Revisión y corrección de la transcripción
Debido a que el texto manuscrito puede ser de difícil lectura, es fundamental que revisemos y corrijamos la transcripción inicial. Este paso mejora significativamente la precisión final.
- Acción del usuario: Leemos la transcripción inicial y comparamos cada palabra con la imagen. Identificamos y corregimos cualquier error en el texto. Luego, se envía la versión corregida.
- Ejemplo de prompt: «Por favor, realiza las siguientes correcciones: [Copia y pega la transcripción completa, pero con los cambios exactos que deseas].»
- Resultado esperado: La herramienta proporcionará una nueva transcripción, validada por el usuario, que se convertirá en la base para todos los análisis posteriores.
Paso 3: Generación de versiones de transcripción alternativas
Una vez que la transcripción sea precisa, podemos solicitar diferentes formatos para la información, lo que es útil para el análisis de datos o la presentación del contenido.
- Acción del usuario: Debemos solicitar al modelo que reestructure la transcripción corregida en diferentes formatos.
- Ejemplo de prompt: «Analiza la transcripción corregida y ofrece otras variantes de transcripción, como un listado de datos clave, un formato de texto plano y una tabla.»
- Resultado esperado: La IA extraerá los datos relevantes (nombre, fecha, monto, etc.) y los presentará en las estructuras solicitadas.
Paso 4: Elaboración de un análisis paleográfico
Para obtener otra visión del documento, podemos solicitar un análisis detallado de sus características físicas y de escritura.
- Acción del usuario: Solicitamos a la herramienta una «nota paleográfica» que analice el documento desde una perspectiva técnica e histórica.
- Ejemplo de prompt: «Por favor, realiza una nota paleográfica, teniendo en cuenta las correcciones efectuadas anteriormente.»
- Resultado esperado: La IA generará un texto analítico que describe la tipografía, la caligrafía, la ortografía de la época, los elementos gráficos (sellos), el estado de conservación del documento y su contexto histórico.
Como es fácil inferirlo, estas herramientas –como Gemini- resultan muy útiles cuando se deben transcribir grandes volúmenes de documentos manuscritos o tipográficos.
Hasta la próxima…
VI. BIBLIOGRAFIA
- Humphries, Mark, Lianne C. Leddy, Quinn Downton, Meredith Legace, John McConnell, Isabella Murray, and Elizabeth Spence. «Unlocking the Archives: Large Language Models Achieve State-of-the-Art Performance on the Transcription of Handwritten Historical Documents.» En SSRN Electronic Journal, 2024. Disponible en https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5006071.
- Humphries, Mark, Lianne C. Leddy, Quinn Downton, Meredith Legace, John McConnell, Isabella Murray, and Elizabeth Spence. «Unlocking the Archives: Using Large Language Models to Transcribe Handwritten Historical Documents.» En arXiv preprint arXiv:2411.03340, November 5, 2024. Disponible en https://arxiv.org/pdf/2411.03340.
- Khan, Arsh, Utsav Rai, Shashank Shekhar Singh, Yukinori Yamamoto, Xabier Granja Ibarreche, Harrison Meadows, and Sergei Gleyzer. «OCR Approaches for Humanities: Applications of Artificial Intelligence/Machine Learning on Transcription and Transliteration of Historical Documents.» En Digital Studies in Language and Literature 1, no. 1-2 (2024): 85-112. Disponible en https://doi.org/10.1515/dsll-2024-0013.
- «Handwriting Recognition in Historical Documents with Multimodal LLM.» En arXiv preprint arXiv:2410.24034v1, October 2024. Disponible en https://arxiv.org/html/2410.24034v1.