Por Héctor José Iaconis
Como lo hemos afirmado en una nota publicada días atrás, la inteligencia artificial (IA) no reemplazará, al menos en corto plazo, la tarea del historiador humano. El rol de este último, por ejemplo, en la interpretación crítica documental, en el análisis de las fuentes primarias y secundarias, puede ser enriquecido por la IA pero no sustituído.
Puede apropiado recordar el término acuñado por el filósofo alemás Hans-Georg Gadamer: “Horizontverschmelzung”, es decir, «fusión de horizontes». Llevado al plano de la tarea del historiador, puede decirse que este interpreta el pasado a partir de una experiencia intelectual propia, mediada por su formación cultural, por el lenguaje que la conforma, por su encuentro con otros horizontes que se entrelazan de alguna manera con el suyo propio; en otras palabras, el horizonte pretérito estudiado se conjuga con su comprensión presente. Esto, desde luego, es una articulación esencialmente humana.
Por cierto, el historiador norteamericano John Lewis Gaddis, en su obra The Landscape of History: How Historians Map the Past, refiere acerca de la forma en que los historiadores elaboran representaciones históricas en su relación con el pasado. Los historiadores humanos experimentan una extrañeza del pasado que se manifiesta al no conocerlo aún con claridad, pero que se va develando en la medida en que avanzan en los estudios y en la indagación de las fuentes. La curiosidad y asombro por descubrir aquello que esconde la bruma del tiempo no ha sido alcanzado aún por las máquinas.
Reiterada esa salvedad, insistimos en que la IA -definida como un conjunto de herramientas, muchas de las cuales son muy conocidas y se encuentran accesibles al público masivo desde hace varios años- puede aportar muy interesantes aplicaciones prácticas en el estudio de la historia de 9 de Julio.
Estos artículos, corresponde aclararlo, no están dirigidos al lector especializado en IA, sino más bien a quienes están comenzando a utilizar estas herramientas o aún no lo han hecho, ofreciéndoles algunas ideas que pueden asociarse a la investigación de la historia local.
OCR E IA MULTIMODAL
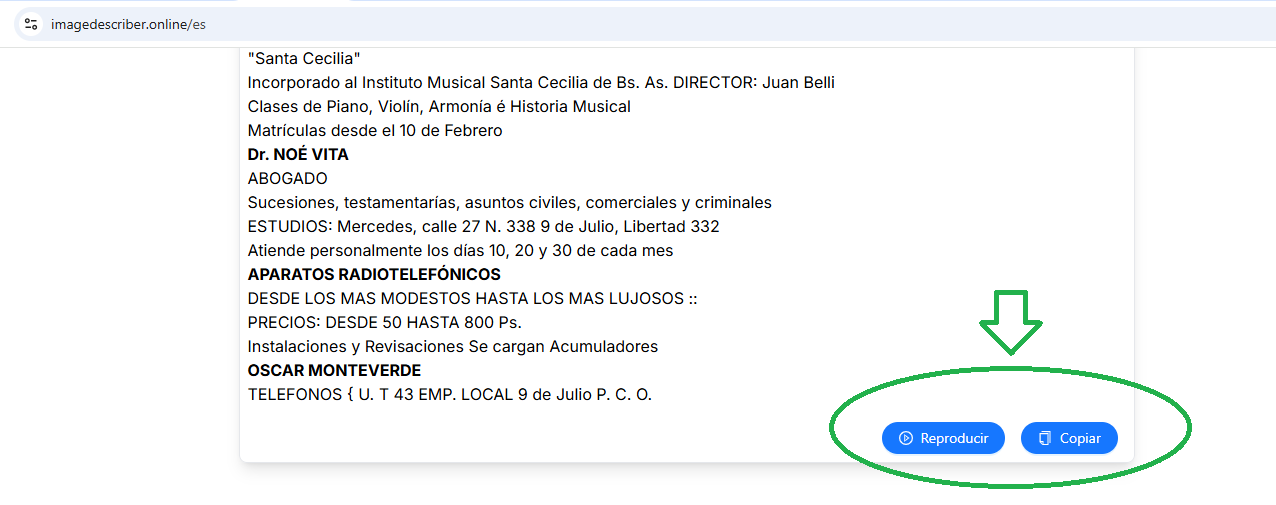
Con la finalidad de ofrecer un ejemplo práctico sobre una de las ventajas que ofrece la IA en el estudio de las fuentes históricas, hemos escogido una página del ejemplar de EL 9 DE JULIO del jueves 13 de mayo de 1926. Se trata de una captura fotográfica realizada con un teléfono móvil, distinguiendo en este caso que no ha empleado otro medio más avanzado o preciso de digitalización.
Tampoco se le efectuó a la imagen edición alguna. Con esto se desea mostrar que, aún cuando la misma no contiene la resolución y características de una página digitalizada según los estándares de calidad usuales, la IA puede brindar resultados aceptables.

Por medio de la tecnología OCR (Reconocimiento Óptico de Caracteres, por sus siglas en inglés: Optical Character Recognition) pudimos obtener una transcripción del texto del documento histórico fotografiado, en un formato editable. Primero, ChatGPT arrojó varios errores de traslación; sin embargo, ImageDescriber fue más preciso, conservando la alineación original, los saltos de línea y otra información de formato, con dos variantes interesantes:

Una segunda versión, alinea el texto, sin tomar en cuenta la disposición de las columnas:

Al mismo tiempo, esta herramienta, además de permitir copiar el texto editable, brinda una versión audible del mismo.
ImageDescriber, lanzada en 2024, es una potente herramienta que combina tecnología OCR con otras capacidades de la IA que permiten mejorar la precisión y velocidad de la extracción de texto; como así también grandes modelos multimodales.
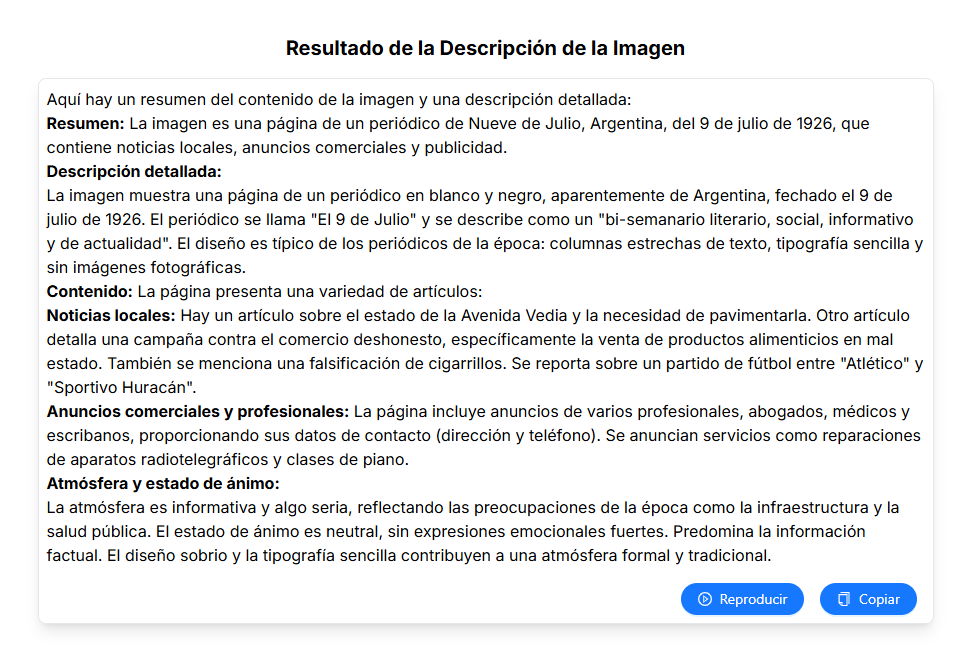
Al solicitarle la instrucción predeterminada (prompt): “Resume el contenido de la imagen en una frase y luego describe en detalle qué hay en la imagen, incluidos objetos, personas, animales, y la atmósfera y el estado de ánimo de la imagen”, la herramienta brindó una respuesta bastante coherente con el contenido del documento, aunque ha confundido la fecha de la publicación (esto revela la recurrente necesidad de confrontar cada una de las informaciones brindadas por la IA con las fuentes históricas originales:
“LA AVENIDA VEDIA”: LA INTERPRETACION DE UNO DE LOS ARTICULOS
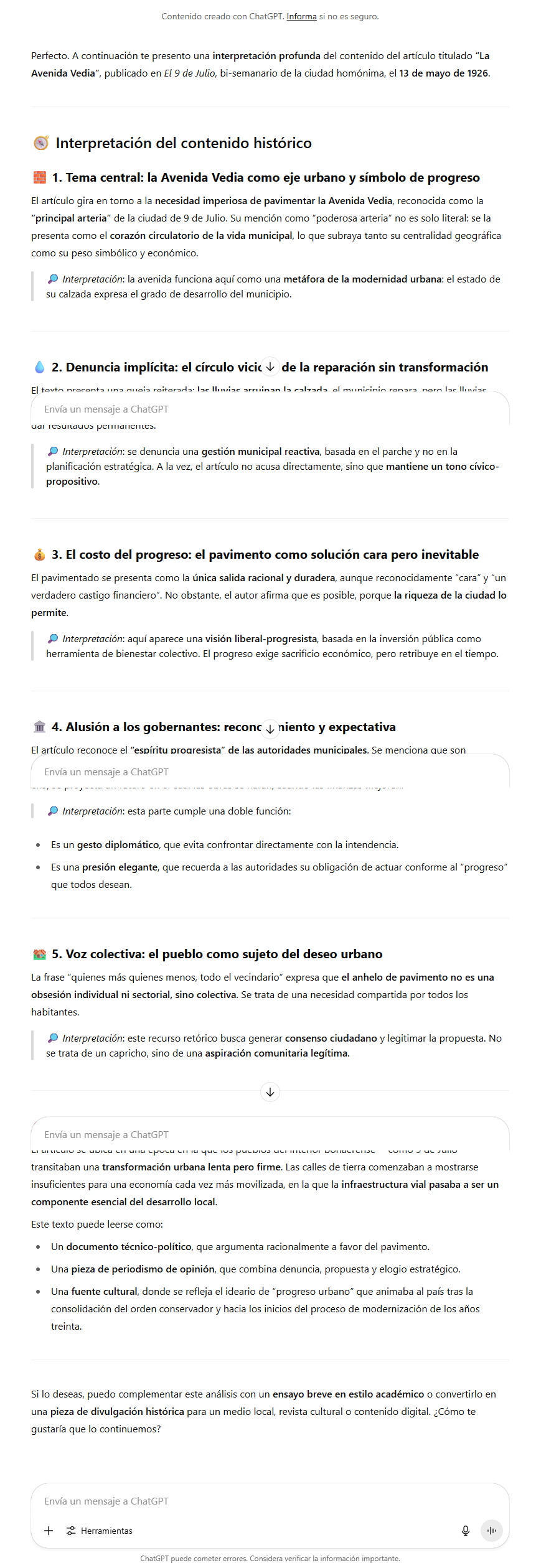
Si escogemos el artículo titulado “La Avenida Vedia” y lo adherimos a ChatGPT solicitando una interpretación del mismo, el resultado también brinda coherencia:

UTILIZANDO GPT-4o
Al hacerlo con GPT-4o, el resultado es el siguiente:
HERRAMIENTAS EMPLEADAS
Para alcanzar esas acciones, fueron empleadas las siguientes herramientas de IA:

Inicialmente, el principal aporte que ha dado la IA para el estudio de este documento, ha sido la posibilidad de convertir el texto en un formato editable. En un proceso de digitalización de documentos masivos, este hecho permite la obtención de un información muy rica que puede ser clasificada, catalogada y trabajada de maneras muy variadas.
Los demás aportes efectuados por la herramienta pueden ser objetables. Por ello, dejamos abierto a la apreciación y opinión de los lectores las consideración que el uso de la IA les sugiere.
Hasta la próxima…
REFERENCIAS BIBLIOGRAFICAS
- Barakat, Bálint, Pepa Atanasova, Emilie Glanois, and Anton Chernyavskiy. 2024. “Multimodal LLMs for OCR, OCR Post-Correction, and Named Entity Recognition in Historical Documents.” arXiv preprint arXiv:2504.00414. Disponible en: https://arxiv.org/abs/2504.00414.
- Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” In Advances in Neural Information Processing Systems 33: 1877–1901. Disponible en: https://papers.nips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
- Chen, Yangyi. 2024. “Multimodal-AND-Large-Language-Models: Paper List about Multimodal and Large Language Models.” GitHub Repository. Disponible en: https://github.com/Yangyi-Chen/Multimodal-AND-Large-Language-Models.
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” arXiv preprint arXiv:1810.04805. Disponible en: https://arxiv.org/pdf/1810.04805.pdf.
- Douillard, Arthur, Matthieu Cord, and Thomas Robert. 2021. “An Embedding View on Zero-Shot Image Classification.” IEEE Transactions on Pattern Analysis and Machine Intelligence. Disponible en: https://arxiv.org/abs/2004.00580.
- Hu, Jinhui, Zhe Shen, Yue Yang, Zhengyuan Koh, Jason Baldridge, Yonatan Bisk, and Yu Wang. 2023. “BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions.” arXiv preprint arXiv:2308.09936. Disponible en: https://arxiv.org/abs/2308.09936.
- Ilharco, Gabriel, Mitchell Wortsman, Ross Wightman, and Ludwig Schmidt. 2023. “OpenFlamingo: An Open-Source Framework for Multimodal Few-Shot Learning.” arXiv preprint arXiv:2304.14198. Disponible en: https://arxiv.org/abs/2304.14198.
- Innovatiana. 2024. “Los 10 Mejores Conjuntos de Datos Multimodales para Modelos de IA.” Innovatiana. Disponible en: https://es.innovatiana.com/post/10-best-multimodal-datasets.
- Kil, Jiyang, Soravit Changpinyo, Xi Chen, Hexiang Hu, Sebastian Goodman, Wei-Lun Chao, and Radu Soricut. 2024. “Context-Independent OCR with Multimodal LLMs: Effects of Image Resolution and Visual Complexity.” arXiv preprint arXiv:2503.23667. Disponible en: https://arxiv.org/abs/2503.23667.
- Liu, Yuliang. 2024. “MultimodalOCR: On the Hidden Mystery of OCR in Large Multimodal Models (OCRBench).” GitHub Repository. Disponible en: https://github.com/Yuliang-Liu/MultimodalOCR.
- Liu, Yuliang, Zhiwei Li, Meng Huang, Biao Yang, Weisheng Yu, Chengquan Li, Xinyuan Yin, Cong Liu, Lianwen Jin, and Xiang Bai. 2024. “OCRBench: On the Hidden Mystery of OCR in Large Multimodal Models.” Science China Information Sciences. Disponible en: https://arxiv.org/abs/2305.07895 y https://link.springer.com/article/10.1007/s11432-024-4235-6.
- Lu, Jiasen, Dhruv Batra, Devi Parikh, and Stefan Lee. 2021. “12-in-1: Multi-Task Vision and Language Representation Learning.” arXiv preprint arXiv:1912.02315. Disponible en: https://arxiv.org/pdf/1912.02315.pdf.
- Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, and Ilya Sutskever. 2021. “Learning Transferable Visual Models From Natural Language Supervision.” In Proceedings of the International Conference on Machine Learning (ICML). Disponible en: https://arxiv.org/pdf/2103.00020.pdf.
- Sanh, Victor, Albert Webson, Colin Raffel, Stephen H. Bach, Lintang Sutawika, Zaid Alyafeai, Yacine Jernite, et al. 2021. “Multitask Prompted Training Enables Zero-Shot Task Generalization.” arXiv preprint arXiv:2110.08207. Disponible en: https://arxiv.org/abs/2110.08207.
- Yin, Daoyang, Jingyu Fu, Aohan Zhou, Jinpeng Zhang, Zihan Zheng, Jianhang Luo, and Shengding Huang. 2024. “A Survey on Multimodal Large Language Models.” National Science Review 11, no. 12: nwae403. Disponible en: https://academic.oup.com/nsr/article/11/12/nwae403/7896414.
- Zhu, Yuke, Hao Liu, Amanda Askell, and Yi Tay. 2023. “MiniGPT-4: Enhancing Vision-Language Understanding with Advanced LLMs.” arXiv preprint arXiv:2304.10592. Disponible en: https://arxiv.org/abs/2304.10592.